Team Members: Hongjin Yu
The ARC-AGI (Abstraction and Reasoning Corpus) is a benchmark for testing general intelligence published in 2019 by François Chollet. Specifically it tests an AI's ability to solve abstract visual tasks with very limited data—typically only 2-6 examples per task. Unlike traditional machine learning, which depends on large datasets to infer patterns, ARC’s small example size makes such models ineffective. Human’s can easily solve over 80% of ARC tasks, while state-of-the-art computer programs have yet to surpass 50%. This is in stark contrast with most other machine learning benchmarks where computers have reached or surpassed humans within years of benchmark publication.
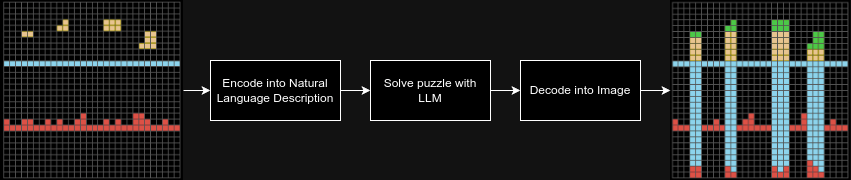
Pretrained LLMs, which have demonstrated one-shot learning capabilities, could be better suited for ARC since once trained, they don't require vast amounts of training data for solving novel tasks. By converting visual ARC tasks into natural language descriptions, LLMs can apply their reasoning abilities to solve the problem. Afterward, the solution can be converted back into visual form, bypassing LLMs' visual limitations and overcome the weaknesses of traditional machine learning models that rely on copious amounts of training data.